
AI agents have transformed how we approach software quality and testing. We came up with a list of use cases where we leveraged this technology to improve the software quality and speed.
And we chose a low-hanging, business-critical use case of automating APIs. The objective is to create as many API automated tests as possible and add them to our regression suite.
We started with an ambitious goal: to automate over 85% of our API test cases with 90% accuracy.
We recognized that AI represents a fundamental shift in how we approach quality engineering, enabling us to scale our testing efforts exponentially while maintaining cost efficiency. The API Automation Agent (api-agent) emerged from this initiative.
API testing
Modern software development demands rigorous API testing at multiple levels. Integration testing validates that different system components work together correctly, ensuring APIs interact seamlessly with databases, external services, and internal microservices.
Release regression testing verifies that new code changes haven’t broken existing functionality and contracts, a critical concern as systems grow in complexity.
Traditional approaches to API testing face significant challenges:
- Manual test creation is time-consuming and requires deep technical knowledge of API contracts, request/response structures, and test frameworks.
- Test maintenance becomes increasingly difficult as APIs evolve, requiring constant updates to keep pace with schema changes.
- Coverage gaps emerge as teams struggle to write comprehensive test suites for every endpoint and scenario.
- Regression testing demands significant effort to execute hundreds or thousands of test cases before each release.
Our API automation strategy needed to address these challenges while scaling with our growing platform. We needed an approach that could generate tests rapidly, adapt to API changes automatically, and provide comprehensive coverage across integration and regression scenarios.
Introducing
API Agent
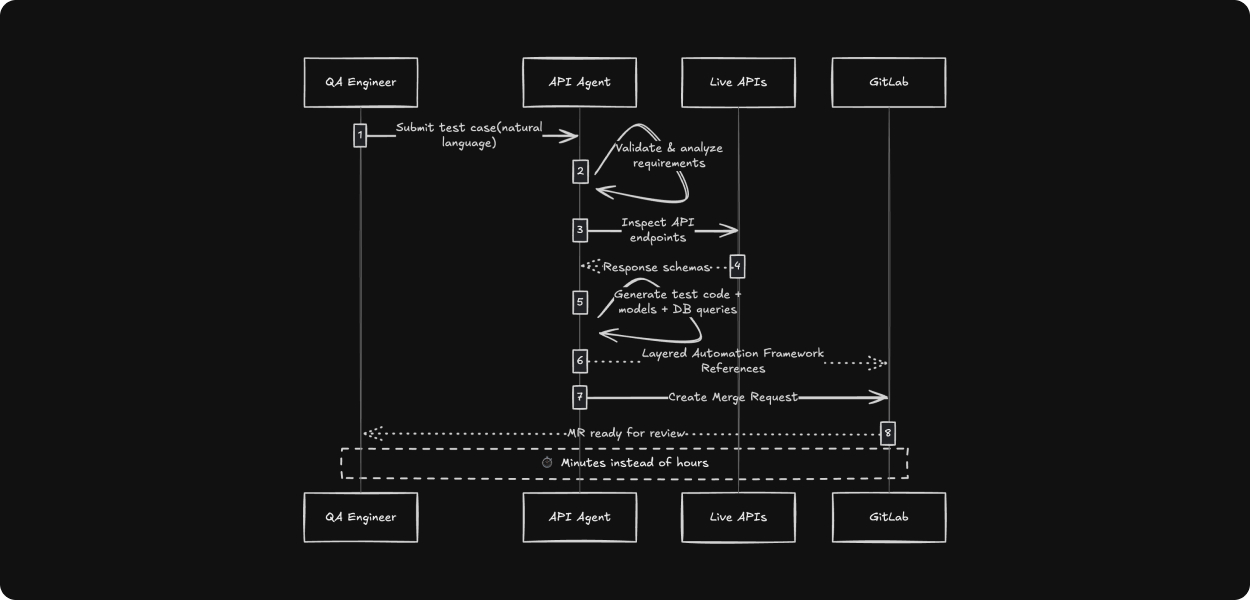
The API Agent is an AI-driven workflow that automates the entire lifecycle of API test creation and maintenance. Rather than requiring engineers to manually write test code, the agent takes natural language test specifications from TestRail and autonomously generates executable test code that follows our established testing frameworks and coding conventions.
What sets API Agent apart from traditional code generation tools is its end-to-end automation. The agent doesn’t just generate test code, it:
- Accepts the test case written in natural language with detailed steps.
- Validates test requirements and identifies ambiguities before code generation.
- Automatically creates supporting code artifacts, including request/response models, service methods, and database validation queries.
- Integrates with GitLab to create merge requests with all generated code.
- Provides observability through Postgres tracking and Slack notifications.
The agent processes test specifications that include test steps, expected results, and test data. It intelligently determines what code needs to be created or modified, inspects live API responses to understand data structures, and generates production-ready test code that integrates seamlessly into our existing test suites.
High-level architecture and design
From the project’s inception, we’ve treated agent performance evaluation as a first-class concern. Our guiding principle is that the API Agent should consistently perform at or above the level of our manual test creation process. To evaluate its performance, we established key success metrics and implemented continuous monitoring.
Evaluation framework
We measure API Agent performance across four dimensions:
- Productivity: Number of tests successfully automated within a given period.
- Correctness: Percentage of generated tests that fit our automation framework standards.
- Maintainability: How well generated code follows our conventions and remains stable across API changes.
- Cost-effectiveness: Infrastructure and compute costs compared to manual test development efforts.
Evaluation framework
Our tuning process involves multiple feedback loops:
- LLM Evaluation with Braintrust: We use Braintrust to perform systematic evaluation on tool callings and prompt handling. Insights from these evaluations inform prompt engineering improvements and guide retry logic.
- Build and test feedback: The agent learns from build failures during the workflow. When generated code fails to compile, this feedback is captured in our Postgres tracker along with error details. We analyze failure patterns to improve preprocessing validation and code generation prompts.
- Code review feedback: Human reviewers provide qualitative feedback through merge request comments. We track common review issues and use them to enhance agent instructions and templates.
- Continuous monitoring: Our Postgres tracking database captures comprehensive metrics for every test generation attempt: success/partial/failure status, token usage, error types, generation time, and test execution results. We monitor these metrics over time to detect regressions and identify optimization opportunities.
- Token optimization: We employed multiple strategies to mitigate context rot, including prompt caching, tool batching, and reducing output sizes.
Results
and Impact
Today, API Agent has significantly enhanced our API testing capabilities. The results speak to both the technical effectiveness of the approach and the business impact.
Quality impact
The agent has improved our overall testing posture:
- Integration test coverage has expanded significantly as the cost of creating tests has dropped.
- Database validation queries are generated automatically, improving assertion depth.
- Test code consistency has improved, as all generated code adheres to the same patterns and conventions
Developer experience
API Agent has fundamentally changed how our teams approach API testing:
- QA engineers can specify tests in natural language rather than writing code.
- Developers receive comprehensive test coverage for new APIs without writing test boilerplate.
- Code reviews focus on test logic rather than framework mechanics.
- Team velocity has increased as test creation no longer bottlenecks feature delivery.
Looking forward
We have fully adopted API Agent in our daily work, and the results are shown in a few metrics:
- Coverage: Over 85% of our API test cases are now automated using API Agent
- Accuracy: Generated tests achieve 90%+ correctness, with most failures caught during automated build validation.
- Efficiency: Test creation time reduced from hours or days to minutes.
- Scalability: New tests can be added within 15-30 minutes from TestRail specification to executable code.
- Adoption: In a couple of months, over 150 MRs were merged, automating over 80+ test cases and saving over 200+ hours of work.
The success of API Agent demonstrates that AI can augment human expertise in complex technical domains.
By automating the mechanical aspects of test creation while preserving human oversight through code review, we’ve achieved a scalable approach to API quality that positions us for continued growth.
Next, we are building multiple AI agents focusing on other testing use cases, which will be published in the near future.
Structured products are complex investment vehicles that involve significant risks and may not be suitable for all investors. These securities are typically unsecured debt obligations of the issuing bank and are subject to the credit risk of the issuer. Structured products are not deposits, are not insured by the FDIC, and are not guaranteed by any bank or government agency.
Investment returns and principal repayment depend on the performance of one or more underlying assets and on the terms of each specific note. Any references to defined outcomes, income potential, or downside protection are hypothetical and not guaranteed. Structured products may have limited or no secondary market and should generally be held to maturity.
Altruist Financial LLC (“Altruist”) does not issue structured products. All structured notes available through Altruist are issued by third-party banks and distributed through external wholesalers. Altruist provides trade processing, custody, and reporting functionality only and does not recommend or endorse any particular issuer, wholesaler, or product.
Fees, costs, and embedded issuer charges may apply and could reduce overall returns. Please refer to the Altruist Financial LLC Fee Schedule and the offering documents provided by the product issuer for additional information.
Structured products are intended for investors who understand the risks associated with derivative-based investments. Advisors are responsible for assessing suitability prior to recommending any structured product investment.
